
CONVOLUTIONAL NEURAL NETWORKS
I still remember the moment I first realized that the world I see with my eyes could be broken down into something as simple and as profound as a grid of numbers. That might sound odd, but for anyone who has marveled at self-driving cars or futuristic face detectors in sci-fi, it all starts with pixels and convolutional neural networks (CNNs).

What Really Is an Image?
An image is not just pretty colors and shapes. To a computer, it is three stacked arrays of numbers: red, green, and blue. Each value sits between 0 and 255. Imagine a 1920 by 1080 image: that is a 1920-column by 1080-row grid with three numbers per pixel (the RGB channels). If you scale those numbers down by dividing each by 255, you get a clean range from 0 to 1. That scaling step, called preprocessing, is critical for machine learning, where models work best with well-behaved input.
The CNN Revealed
I like to think of a CNN as a detective scanning an ancient scroll. Instead of words, it scans image patches. Here is how it works, grounded in facts.
As IBM explains, "CNNs use three-dimensional data for image classification and object recognition tasks," and they are built from layers: convolution, pooling, and fully connected layers (IBM).
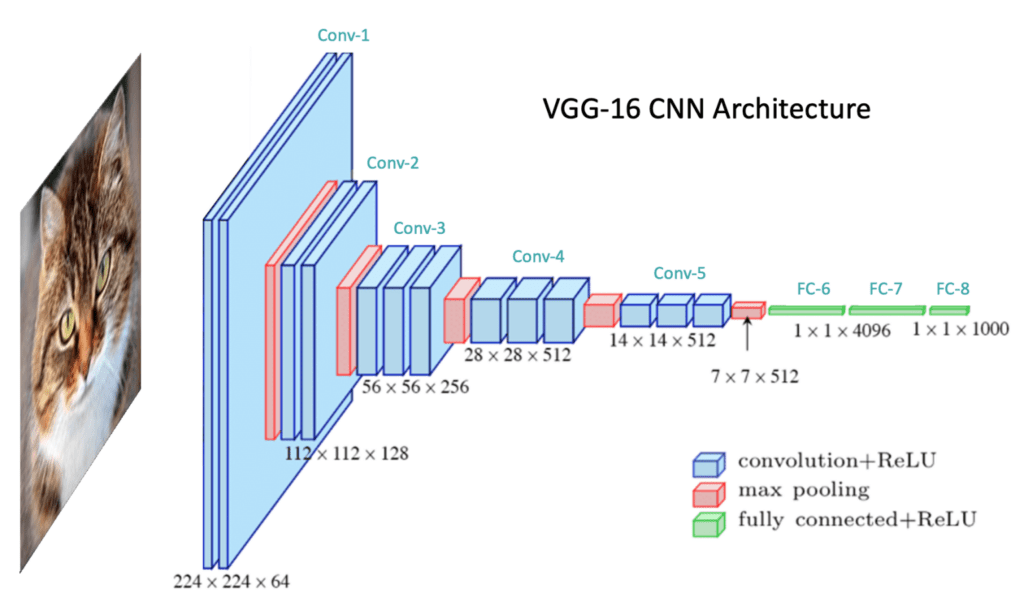
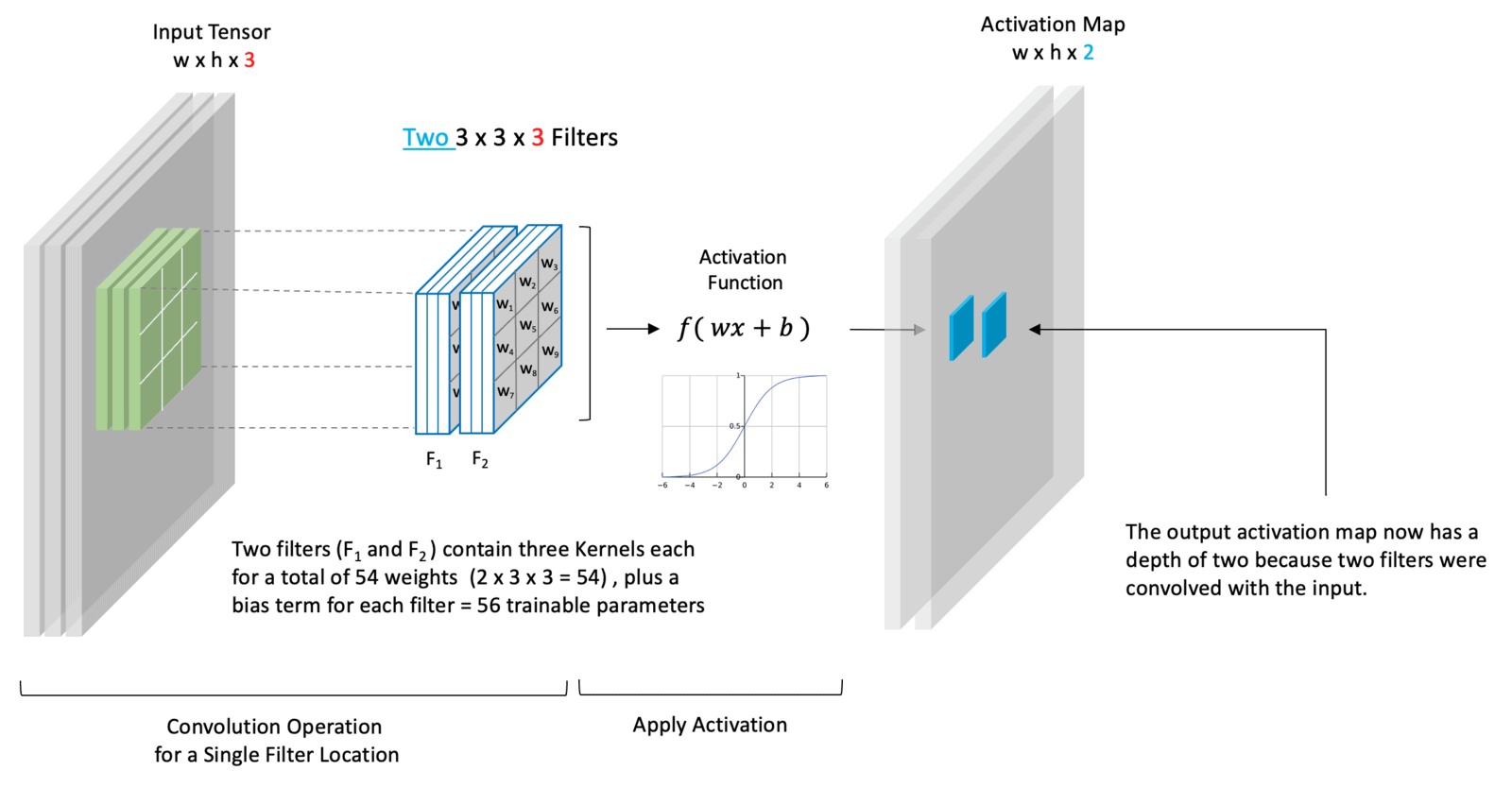
The convolution layer uses small matrices called kernels or filters that slide across the image. Each filter performs a dot product between its values and the corresponding pixel values. That creates numbers that form a new grid called a feature map (Wikipedia, DataCamp). As TechRadar puts it, early layers identify "basic elements like lines and curves," while deeper layers combine these into shapes such as wheels or ears, and eventually recognize complex objects like cars or pets (TechRadar).
The pooling layer, often using a method called max pooling, then simplifies things. It keeps the highest value in each small region of the feature map. This reduces size while preserving important information (Wikipedia, Medium).
Finally, the values are flattened into a one-dimensional array and sent into a fully connected network that makes the decision. That sequence from pixels to prediction is how CNNs see and understand images.
Why This Matters and Where It Came From
CNNs are not science fiction. They are inspired by how our brains process vision. The architecture mirrors the structure of the visual cortex, where neurons respond to edges, textures, and gradually more complex shapes (DataCamp, Wikipedia).
One of the first CNNs, LeNet-5, was created by Yann LeCun in the 1980s. It could read handwritten digits and was used in ATMs to process tens of thousands of checks every day (Wikipedia). In 2012, AlexNet by Krizhevsky, Sutskever, and Hinton made CNNs famous by winning the ImageNet competition with much lower error rates, powered by GPUs (Wikipedia).
Later came models such as VGG-16 and VGG-19 from the Oxford Visual Geometry Group, and EfficientNet from Google AI, which improved accuracy while optimizing network size and scaling (Wikipedia, Arxiv).
CNNs in the Wild
These models are now everywhere. CNNs power the face unlock on your phone, the vision systems in self-driving cars, automatic photo tagging, and even medical imaging for detecting tumors (TechRadar, Springer). As one Springer review noted, CNNs "have become dominant in various computer vision tasks," and they are used in radiology for lesion detection, segmentation, and diagnostics (Springer).
In My Own Words
If I were explaining this to a friend, I would say:
"You know how in detective movies, the screen suddenly highlights a face with a square? That is a CNN scanning pixel patterns. Early layers only learn edges and curves. As you go deeper, the network understands shapes like eyes or wheels, and finally recognizes the full object such as a face, a car, or a cat. The amazing part is that no one programs those rules by hand. The network figures them out from data."
Sources
- IBM: What are convolutional neural networks?
- DataCamp: Introduction to CNNs
- Medium: Step-by-step CNN tutorial
- Wikipedia: Convolutional Neural Network
- Springer: CNNs in Radiology
- TechRadar: CNNs in real-world applications
- Wikipedia: LeNet
- Wikipedia: AlexNet
- Wikipedia: VGGNet
- Arxiv: EfficientNet Paper




More
more
like this
like this
On this blog, I write about what I love: AI, web design, graphic design, SEO, tech, and cinema, with a personal twist.



